Over the last quarter, I took a GPU programming class. For the final project of that class, I worked on accelerating GPT-2 inference using CUDA in a group of 4. Specifically, we found a pure C CPU-only implementation of GPT-2 inference online, and accelerated it using CUDA.
We settled on writing custom CUDA kernels for every operation rather than deferring some of it to the variety of existing libraries to maximize the educational value of the project, as well as set (and achieved) the goal of making it end-to-end, meaning the data is only transferred from host to device once, then the entire inference process happens on the GPU, and then the data is transferred back to device (per token).
The GitHub repository with code and results is here: https://github.com/nika-chuzhoy/cuda-gpt-2.
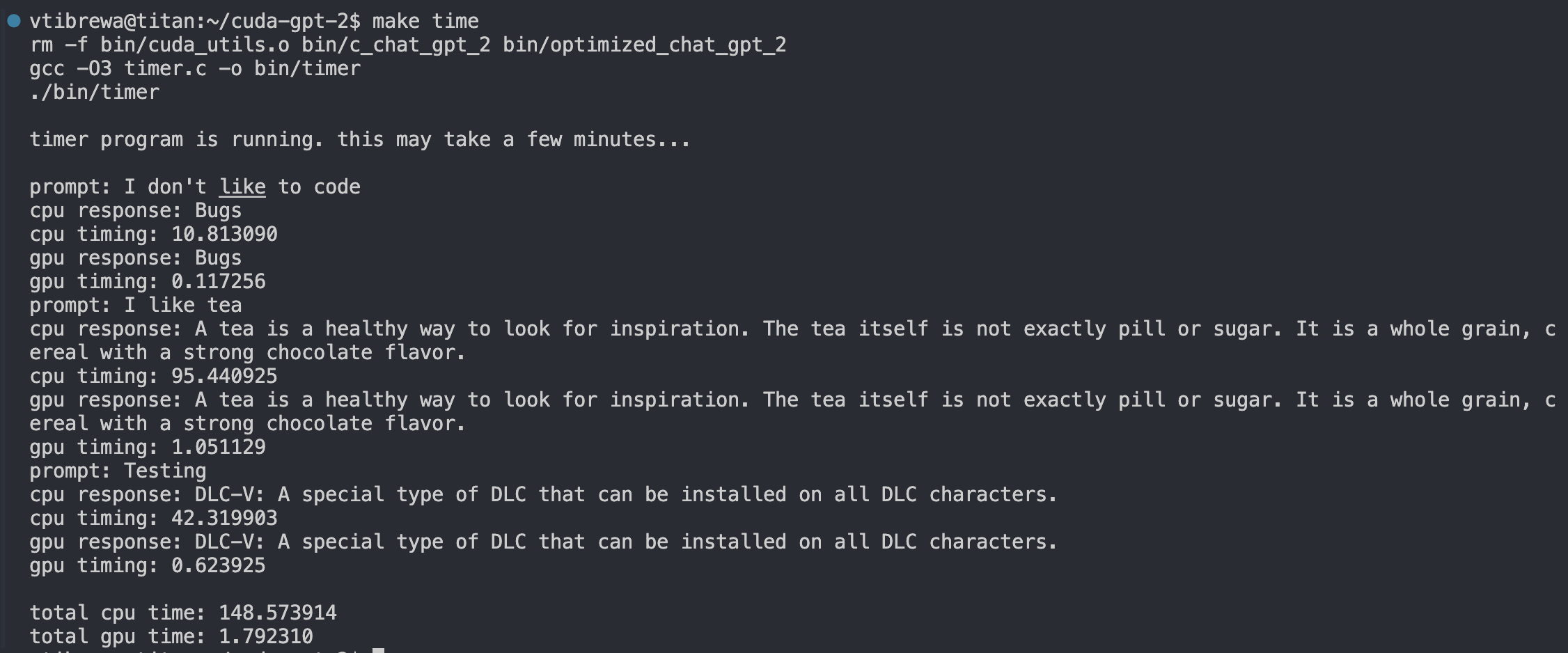
The repository contains the code, a video demonstration of the speedup, instructions for reproduction, and unit tests and kernel-wise speedups. As a preview, here is the test measuring the overall speedup achieved over a few different prompts. The speedup achieved is over 80x!
Results Preview