Over the last quarter, I took an advanced topics in ML class on the topic of LLMs for reasoning. For the final project of that class, I did research on activation steering in a group of 4. We worked on various extensions of the idea of Contrastive Activation Addition (Panickssery et al., 2024 arXiv:2312.06681).
Contrastive Activation Addition computes “behavior vectors” by averaging the difference in residual stream activations between pairs of positive and negative examples of a particular behavior. Then, the LLM can be “steered” to demonstrate more of less of the chosen behavior, by adding the behavior vector times a coefficient to the residual stream of the model at inference time.
We extended CAA in 3 ways:
- Apply CAA to Llama-3-8b (original paper is for Llama 2).
- Apply CAA to the task of improving language model reasoning abilities.
- Modify CAA to intervene after Multi-Head Attention rather than after the whole decoder block.
The full report with results is here: https://bit.ly/CAA159.
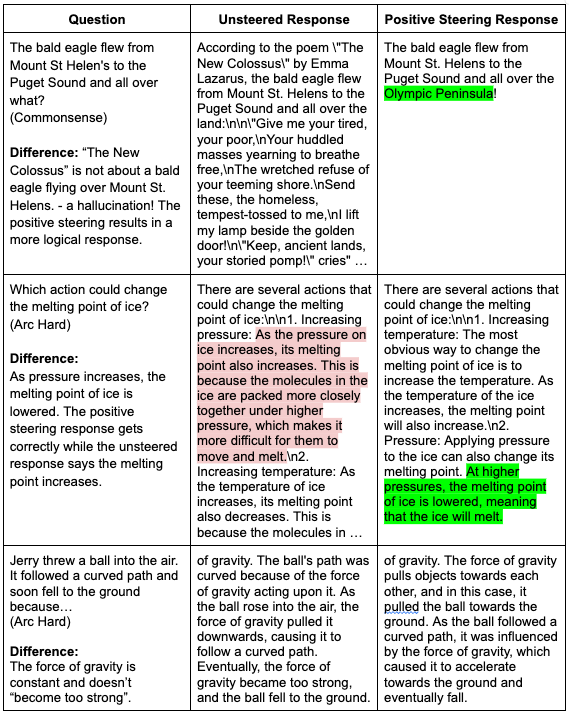
As a preview, here is an example of how postive CAA steering in a “reasoning” direction leads to qualitative improvement in the model’s open-ended responses to reasoning questions, in addition to better quantitative multiple choice accuracy.
Results Preview